山内研究室 Biomimetic Intelligent System Laboratory
yamauchi[at]cs.chubu.ac.jp研究内容
研究テーマ
メンバー
担当授業
研究室へのアクセス
top page
- 忘れそうな記憶を選択的に再学習する追加学習アルゴリズム(詳細説明)
- 「睡眠」を伴う追加学習アルゴリズム(詳細説明)
- 「興味」を持って学習する機械学習アルゴリズム!(詳細説明)
- 制限付き神経回路の開発と電力制御への応用(詳細説明)
- 組込用学習理論の構築(詳細説明)
1999年の古い研究になりますが、最近のDeep Neural Networkの継続学習にも通じる技術のため、紹介したいと思います。神経回路は一旦学習すると、学習させていない入力に対しても妥当な出力を出す能力(汎化能力)を持 ちます。その半面、一旦学習を終えた神経回路に新しい学習データを追加的に学習させると、過去に学習させた内容を忘却する(Catastrophic Forgetting)現象がが発生します。これを防ぐには過去に覚えたすべてのサンプルを再学習させるのが最も確実な忘却抑制方法ですが、これでは明らかに計算量が爆発的に増えてしまいます。この問題を緩和するため、再学習させるサンプルとして、追加学習によって忘れそうな過去のサンプルだけを選ぼうというのがここで紹介する手法です。忘れそうな記憶は勾配法を使って予測します。そして、それらを想起した上で新奇サンプルと共に織り交ぜて再学習させる追加学習理論[1]です。
構造:
このモデルでは神経回路の横にR-buffer, N-bufferを用意してあり、N-bufferには新奇サンプルを、R-bufferには忘れそうな記憶を神経回路から想起したものを保存します。このR-bufferは現代風に言えばreplay-bufferです。新しいサンプルがN-bufferに保存された後、N-bufferのサンプルを学習させたとしたときに忘却しそうな過去の記憶(サンプル)を思い出し、それをR-bufferに貯めます。さらにR-bufferに貯まったサンプルを再学習することでさらに影響を受ける記憶もあります。それらも想起してR-bufferに追加します。この想起過程が終了したら二つのバッファの中身を織り交ぜながら勾配法を使って学習させます。
過去の記憶の想起:
この手法の肝になるのは過去の記憶の想起です。「忘れそう」な記憶を見つけるため、干渉量なる指標を定義して I(x)で表します。I(x)は勾配法による学習によって生ずる神経回路の出力変化を推定したベクトルです。定義詳細は文献[1]をご覧下さい。||I(x)||>εIとなるxを探し、対応する神経回路の出力ベクトルと共にR-bufferに保存します。
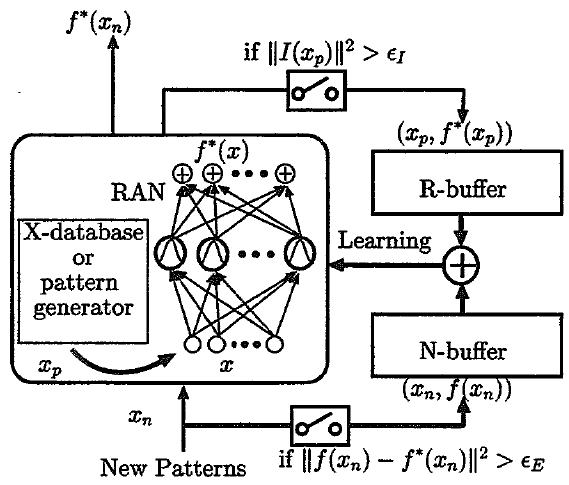
追加学習システムの構造 (文献[1]から転記)
このモデルは過去のサンプルと新奇サンプルを織り交ぜて学習させるタイプの追加学習法と位置づけられます。最近、Deep Neural Networkの研究者が増えて、似た方式が再発見されるケースがあります。例えばNaive Rehearsal法[2]が挙げられます。このアイデア自体は30年程前からありましたが、最近また浮上してきた手法です。シンプルな構造ながら高い忘却抑制能力が得られる点でかなり実用的な手法です。他にも興味深い方法は数多く提案されているものの、実用性・使い勝手の良さという観点からこのようなリハーサルによる追加学習法は今後も使われていくと私は予想します。何分、元の神経回路の構造や、学習方式は基本的に変えなくて良いのですから。手っ取り早く追加学習システムを構築したいならまずはリハーサル法で試してみると良いでしょう。
開発秘話:
当初、この理論は3層パーセプトロンを対象として開発がスタートしました。学習によって変化するパラメータを誤差曲面の勾配から推定し、干渉を受ける領域を推定するのですが、パーセプトロンの場合は各ニューロンが表現する識別境界面にそって∞遠方まで干渉を受けてしまうことになります。想起するべき記憶パターンは、本来なら無限個のサンプルとなってしまうのです。実際には、この無限個のサンプルの中で、過去の学習時に提示されたサンプルか、もしくはそれに近いサンプルとなるべきです。ところが、パーセプトロンの場合、ある任意の入力が過去に提示されたサンプルなのか、未知の入力なのかの判別方法が当時は思いつかなかったのです※。
これではとても使い物になりそうに無い!そこでGeneralized Radial Basis Function (GRBF)[4]の派生モデルであるResource Allocating Network (RAN)[3]を使ってこれを実現することにしたのです。このモデルを使えば状況に応じてネットワークのサイズを拡張(容量の拡張)が可能であることに加えて、干渉を受ける領域は局在することになります。つまり想起させるべきサンプルもガウス基底関数の中心位置に近いサンプルに限定すれば良いことになります。これはかなり実用的な追加(継続)学習システムではないかと自負しています。
※現在ではAuto-encoderを使ったリハーサル法が開発されています(例えば[5])。
関連主要論文
[1]Koichiro Yamauchi, Nobuhiko Yamaguchi, Naohiro Ishii . "Incremental Learning Methods with Retrieving Interfered Patterns", IEEE TRANSACTIONS ON NEURAL NETWORKS, vol.10, No.6, pp. 1351--1365, November, (1999).
[2] Yen-Chang Hsu, Yen-Cheng Liu, Anita Ramasamy, Zsolt Kira . "Re-evaluating Continual Learning Scenarios: A Categorization and Case for Strong Baselines", in S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, R. Garnett , editors, Advances in Neural Information Processing Systems 31, Curran Associates, Inc., (2018).
[3] John Platt . "A resource allocating network for function interpolation", Neural Computation, vol.3, No.2, pp. 213--225, (1991).
[4] Tomaso Poggio, Federico Girosi . "A Theory of Network for Approximation and Learning", AI Memo / Massachusetts Institute of Technology, Artificial Intelligence Laboratory, vol.1140, pp. 1--78, July, (1989).
[5] Gido M. van de Ven, Hava T. Siegelmann, Andreas S. Tolias . "Brain-inspired replay for continual learningwith artificial neural networks", Nature communications, vol.11, No.4069, pp. 1--14, August, (2020).